Session 4: 3h27m
Gestión descentralizada de datos
Cada microservicio tiene sus propios datos, por lo que la integridad y la coherencia de los datos deben considerarse con mucho cuidado.
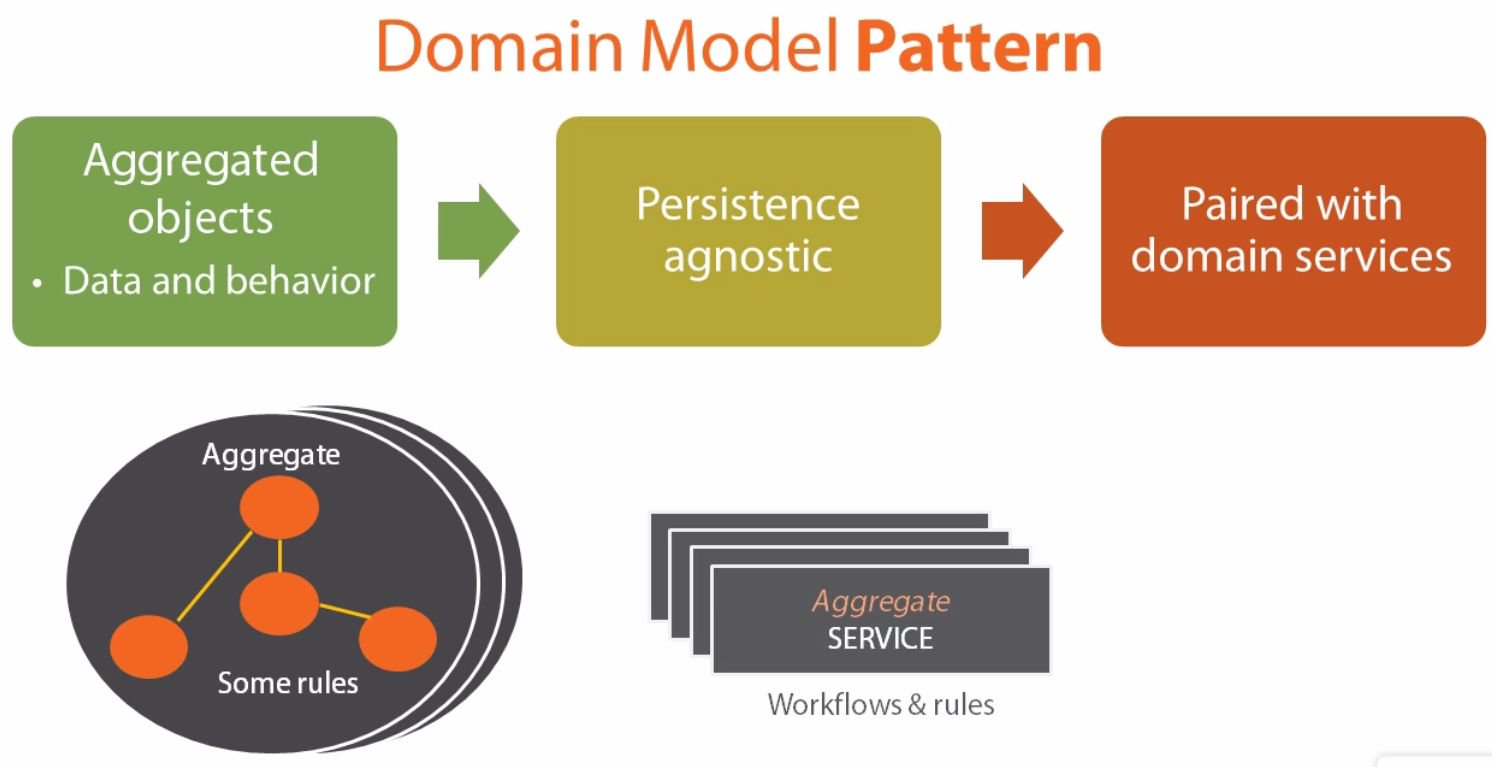
El principio fundamental de la gestión de datos de microservicios es que cada microservicio debe administrar sus propios datos, podemos llamar a este principio como una base de datos por servicio. Eso significa que los microservicios no deben compartir bases de datos entre sí. En lugar de eso, cada servicio debe ser responsable de su propia base de datos, a la que otros servicios no pueden acceder directamente.
Debe compartir datos a través de los microservicios de la aplicación con el uso de API REST.
La razón de este aislamiento es romper las dependencias innecesarias entre microservicios. Si hay una actualización en el esqumea de base de datos de un microservicio, la actualización no debe afectar directamente a otros microservicios, incluso otros microservicios no deben conocer los cambios en la base de datos. Al aislar las bases de datos de cada sevicio, podemos limitar el ámbito de los cambios en los microservicios cuando se producen cambios en el esquema de la base de datos.
También de esta manera, podemos elegir diferentes bases de datos según los microservicios, qué base de datos puede elegir la mejor opción. Llamamos a esto principio de "persistencia políglota".
Patrón de base de datos por servicio

Arquitectura lógica vs Arquitectura física
La creación de microservicios no requiere el uso de ninguna tecnología específica. Por ejemplo, los contenedores de Docker no son obligatorios para crar una arquitectura basada en microservicios. Esos microservicios también se pueden ejecutar como procesos sin formato. Los microservicios son una arquitectura lógica.
La arquitectura lógica y los límites lógicos de un sistema no se asignan necesariamente uno a uno a la arquitectura física o de implementación. Esto puede suceder, pero a menudo no es así.
Por tanto, un microservicio o contexto limitado empresarial es una arquitectura lógica que podría coincidir (o no) con la arquitectura física. Lo importante es que un microservicio o contexto limitado empresarial debe ser autónomo y permitir que el código y el estado ser versionen, implementen y escalen de forma independiente.