Sesión 5: 3h39m
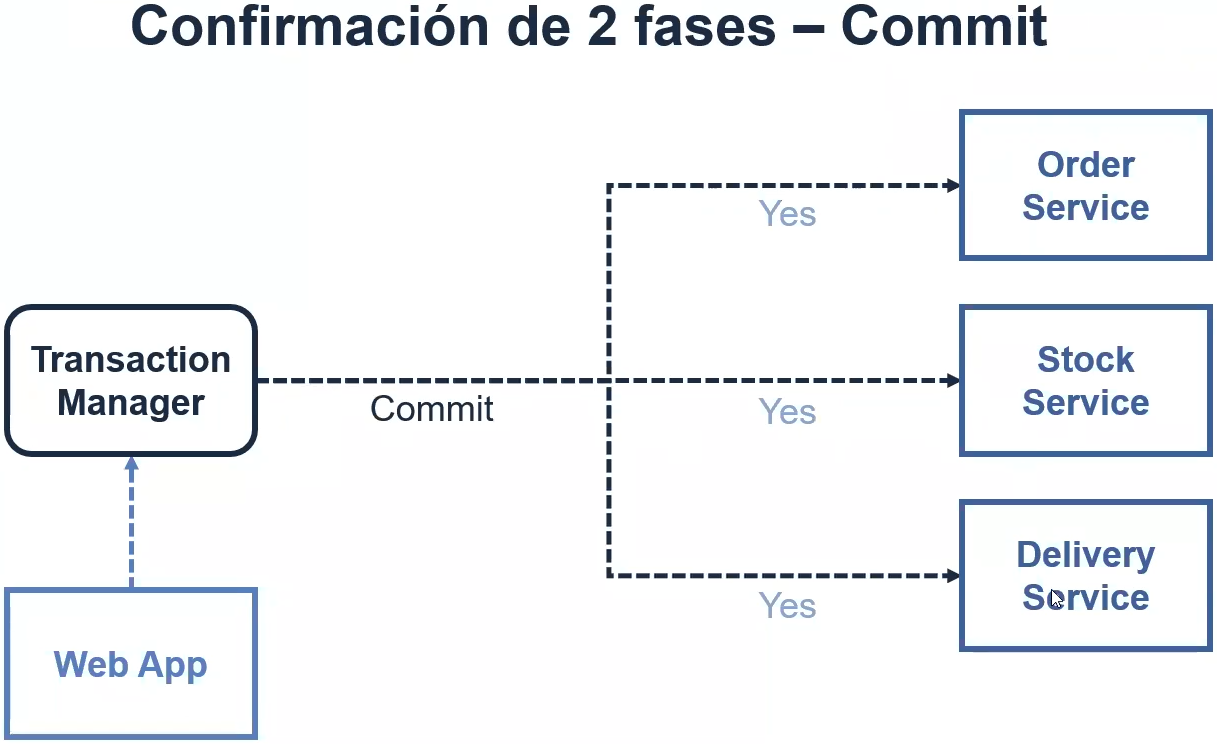
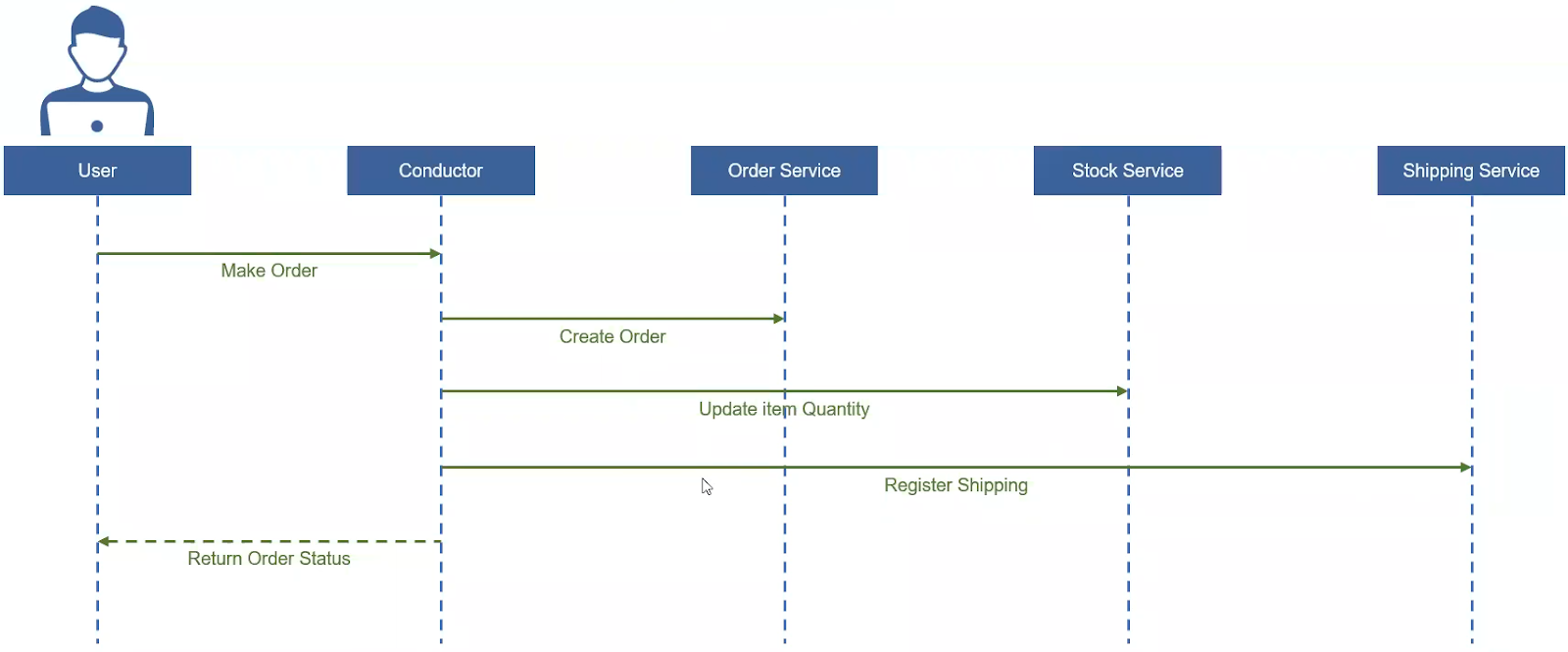
Existen 2 formas de implementar SAGA.
SAGA - Corografía
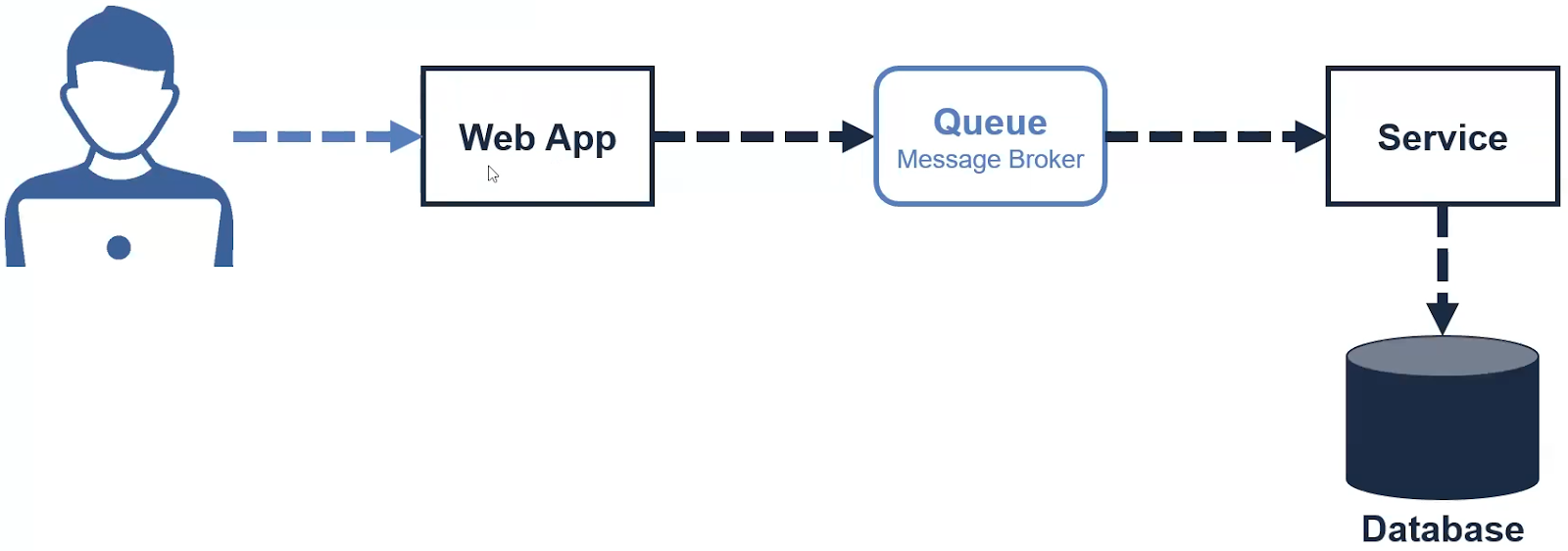
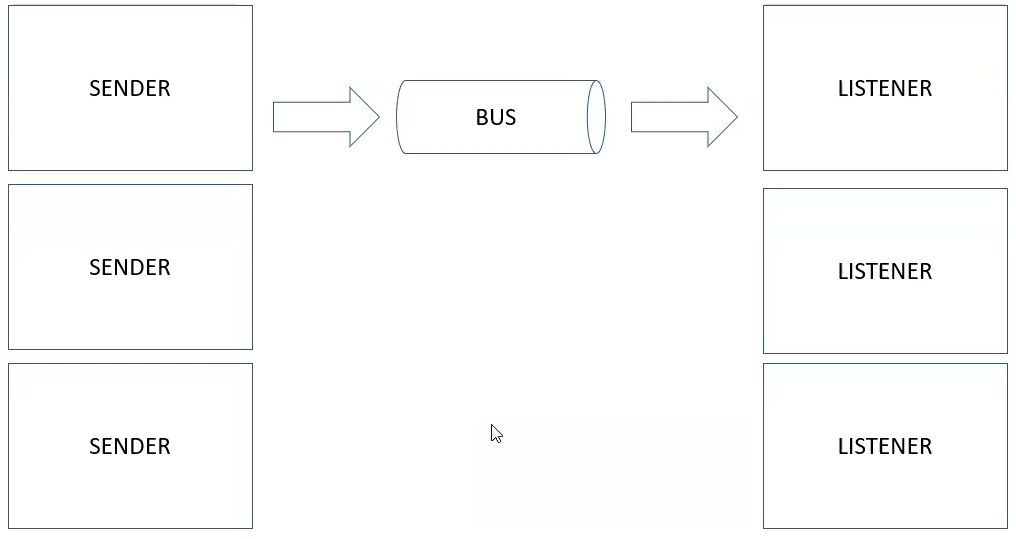
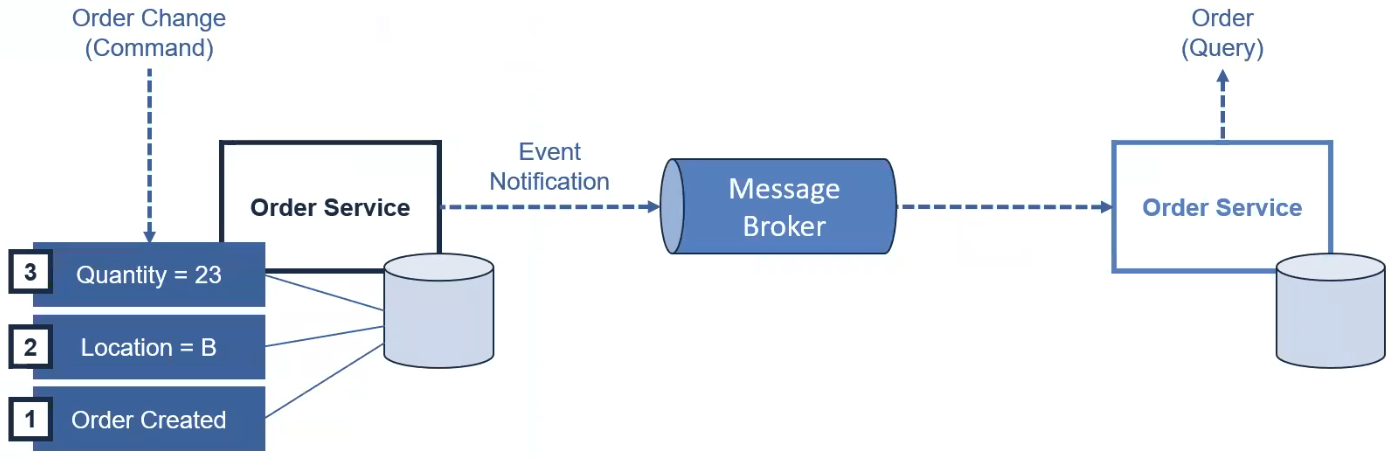
La coreografía es una secuencia de pasos o movimientos en la danza... y también es similar en el desarrollo de software si aplicas SAGA - Coreografía. Con este enfoque, cada servicio produce y escucha los eventos de otros servicios, en función del evento de otros servicios decidirá la siguiente acción. La saga utiliza un bus de mensaje para comunicarse.Flujo de SAGA-Choreography
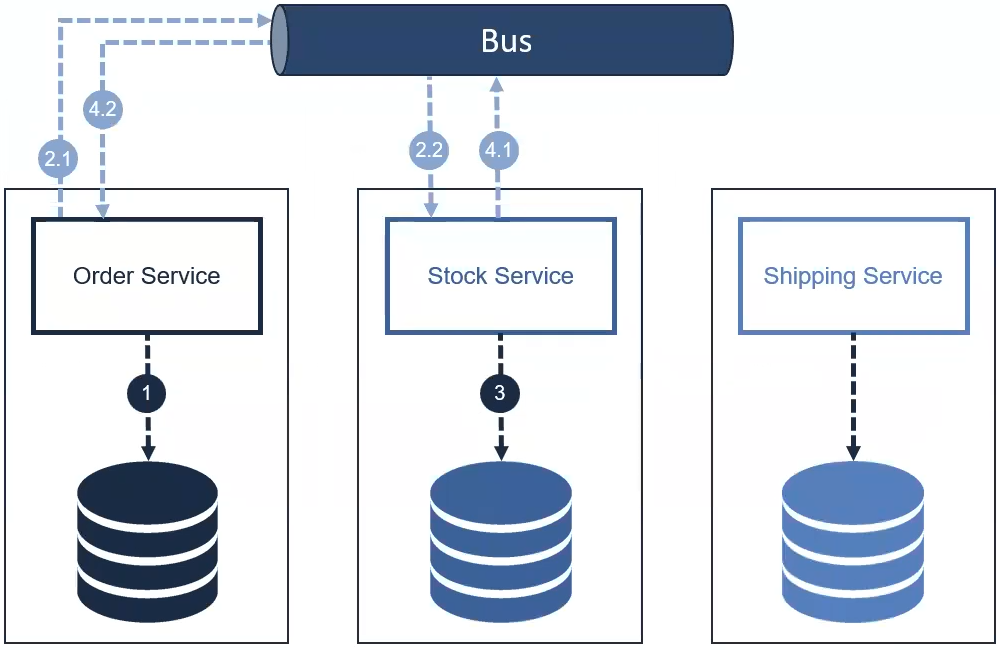
- El servicio de pedidos crea un registro en la base de datos con el estado "Verificando".
- El servicio de pedidos publica un evento "El pedido se ha creado correctamente" y el servicio de Stock escuchará este evento.
- El servicio de stock actualiza el número de productos de la base de datos stock.
- El servicio de stock publica un evento "El producto se ha actualizado correctamente" y el servicio de pedidos y el servicio de envío escuchará este evento.
- El servicio de pedido cambiará el estado del pedidio a "Envío"
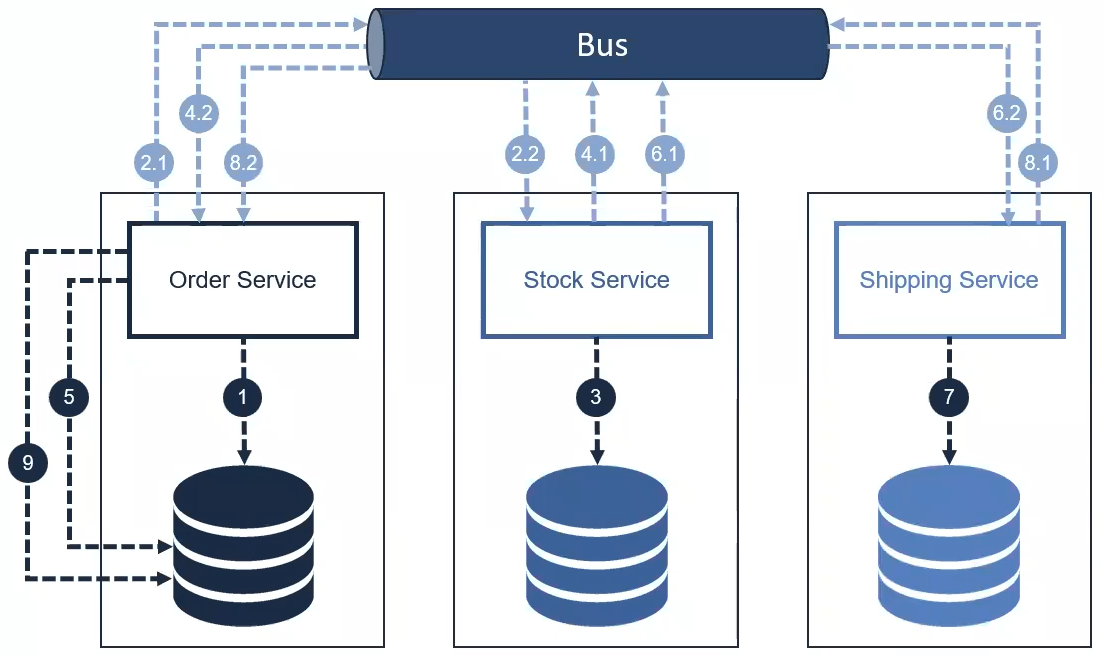
- El servicio de stock publica un evento "El producto se ha actualizado correctamente" y el servicio de pedidos y el servicio de envío escucharán este evento.
- El servicio de envío crea un registro en la base de datos envíos.
- El servicio de envío publica un evento "El envío se ha registrado correctamente" y el servicio de pedidos escuchará este evento.
- El servicio de Pedido cambia el estado del pedido a "Finalizar".
Flujo de Rollback en SAGA-Choreography (Escenario 1)
Hay un error con Stock Service.
- El servicio de pedidos crea un registro en la base de datos con el estado "Verificando"
- El servicio de pedidos publica un evento "El pedido se ha creado correctamente" y el servicio de Stock escuchará este evento.
- El servicio de stock actualiza el número de productos de la base de datos de stock. Pero hay un error inesperado al guardar el registro del producto.
- Stock Service publica un evento de "reversión" "Error al actualizar el número de productos en stock".
- El servicio de pedido cambiará el estado del pedido a "Error".

Flujo de Rollback en SAGA-Choreography (Escenario 2)
El servicio de pedidos y el servicio de stock se ejecutan correctamente. Hay un error con el servicio de envío.
- El servicio de envío crea un registro en la base de datos de envío. Pero hay un error inesperado al guardar.
- El servicio de envío publica un evento de "reversión" "Error al registrar el servicio de envío" y tanto el servicio de pedidos.
- El servicio de envío publica un evento de "reversión" "Error al registrar el servicio de envío" y tanto el servicio de stock.
- El servicio de pedido cambiará el estado del pedido a "Error".
- El servicio de stock actualiza el número del producto.
Flujo de SAGA-Choreography
- Tenga en cuenta que es crucial definir un ID compartido común para cada transacción, de modo que cada vez que lance un evento, todos los oyentes puedan saber de inmediato a qué transacción se refiere.
- Las compensaciones también pueden fallar. Pueden haber compensaciones reintentables.
Ventajas y desventajas de SAGA - Coreografía
- La coreografía es la forma más sencilla de implementar el patrón SAGA. Es muy fácil de entender y no requiere demasiado esfuerzo para construir. Cada transacción local en cadena es independiente ya que no tienen conocimiento directo entre sí. Si su transacción distribuida solo incluye de 2 a 4 transacciones locales (servicios), entonces la coreografía es una opción muy adecuada.
- Tener demasiadas transacciones locales hará que el seguimiento de qué servicios escuchan qué eventos, se vuelva complejo. Con la muestra anterior, solo tenemos 3 transacciones locales pero más de 10 pasos para manejar. Imaginemos que cuando tengamos 10 transacciones ¿qué sucederá?
Demo SAGA Choreography